1、高并发情况下,生成分布式全局id策略
2、利用全球唯一UUID生成订单号优缺点3、基于数据库自增或者序列生成订单号4、数据库集群如何考虑数据库自增唯一性5、基于Redis生成生成全局id策略6、Twitter的Snowflake算法生成全局id7、基于Zookeeper生成全局id
高并发情况下,生成分布式全局id策略
1、注意幂等性且全局唯一性
2、注意安全性,不能被猜疑3、趋势递增性订单号命名规则:比如“业务编码 + 时间戳 + 机器编号[前4位] + 随机4位数 + 毫秒数”。
利用全球唯一UUID生成订单号
UUID基本概念:UUID是指在一台机器上生成的数字,它保证对在同一时空中的所有机器都是唯一的。UUID组成部分:当前日期和时间+时钟序列+随机数+全局唯一的IEEE机器识别号全局唯一的IEEE机器识别号:如果有网卡,从网卡MAC地址获得,没有网卡以其他方式获得。UUID优缺点:优点: 简单,代码方便 生成ID性能非常好,基本不会有性能问题 全球唯一,在遇见数据迁移,系统数据合并,或者数据库变更等情况下,可以从容应对缺点: 没有排序,无法保证趋势递增 UUID往往是使用字符串存储,查询的效率比较低 存储空间比较大,如果是海量数据库,就需要考虑存储量的问题。 传输数据量大
UUID不需要联网生成,redis需要。
基于数据库自增方式
实现思路:利用数据库自增或者序列号方式实现订单号
注意:在数据库集群环境下,默认自增方式存在问题,因为都是从1开始自增,可能会存在重复,应该设置每台不同数据库自增的间隔方式不同。优点: 简单,代码方便,性能可以接受。 数字ID天然排序,对分页或者需要排序的结果很有帮助。缺点: 不同数据库语法和实现不同,数据库迁移的时候或多数据库版本支持的时候需要处理。 在性能达不到要求的情况下,比较难于扩展。 在单个数据库或读写分离或一主多从的情况下,只有一个主库可以生成。有单点故障的风险。 分表分库的时候会有麻烦。
数据库集群如何考虑数据库自增唯一性
在数据库集群环境下,默认自增方式存在问题,因为都是从1开始自增,可能会存在重复,应该设置每台节点自增步长不同。
查询自增的步长SHOW VARIABLES LIKE 'auto_inc%'修改自增的步长SET @@auto_increment_increment=10; 修改起始值SET @@auto_increment_offset=5;假设有两台mysql数据库服务器节点①自增 1 3 5 7 9 11 ….节点②自增 2 4 6 8 10 12 ….注意:在最开始设置好了每台节点自增方式步长后,确定好了mysql集群数量后,无法扩展新的mysql,不然生成步长的规则可能会发生变化。
MySQL1 1 2 3
MySQL2 1 2 3
方法1 读写分离
方法2 设置自增步长 需要提前设置好步长 否则如果新增一台MySQL就麻烦了
如果想提高扩展性 采用UUID方式作为主键
基于Redis生成生成全局id策略
因为Redis是单线的,天生保证原子性,可以使用Redis的原子操作 INCR和INCRBY来实现优点: 不依赖于数据库,灵活方便,且性能优于数据库。 数字ID天然排序,对分页或者需要排序的结果很有帮助。缺点: 如果系统中没有Redis,还需要引入新的组件,增加系统复杂度。 需要编码和配置的工作量比较大。注意:在Redis集群情况下,同样和Redis一样需要设置不同的增长步长,同时key一定要设置有效期可以使用Redis集群来获取更高的吞吐量。假如一个集群中有5台Redis。可以初始化每台Redis的值分别是1,2,3,4,5,然后步长都是5。各个Redis生成的ID为:A:1,6,11,16,21B:2,7,12,17,22C:3,8,13,18,23D:4,9,14,19,24E:5,10,15,20,25 比较适合使用Redis来生成每天从0开始的流水号。比如订单号=日期+当日自增长号。可以每天在Redis中生成一个Key,使用INCR进行累加。如果生成的订单号超过自增增长的话,可以采用前缀+自增+并且设置有效期
当前日期-5位自增
统一时间 最多生成10w-1个不重复的
假设双十一 每秒99w订单
package com.toov5.controller;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.data.redis.core.RedisTemplate;import org.springframework.data.redis.support.atomic.RedisAtomicLong;import org.springframework.web.bind.annotation.RequestMapping;import org.springframework.web.bind.annotation.RestController;@RestControllerpublic class OrderController { @Autowired private RedisTemplate redisTemplate; @RequestMapping("/order") public Long order(String key) { RedisAtomicLong redisAtomicLong = new RedisAtomicLong(key, redisTemplate.getConnectionFactory() ); long andIncrement = redisAtomicLong.getAndIncrement(); return andIncrement; }} 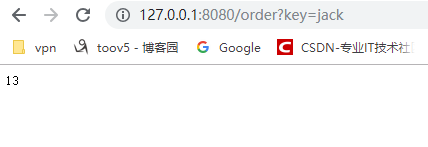
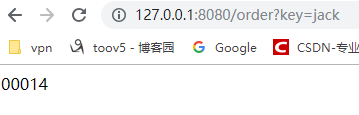
补零:
import org.springframework.beans.factory.annotation.Autowired;import org.springframework.data.redis.core.RedisTemplate;import org.springframework.data.redis.support.atomic.RedisAtomicLong;import org.springframework.web.bind.annotation.RequestMapping;import org.springframework.web.bind.annotation.RestController;@RestControllerpublic class OrderController { @Autowired private RedisTemplate redisTemplate; @RequestMapping("/order") public String order(String key) { RedisAtomicLong redisAtomicLong = new RedisAtomicLong(key, redisTemplate.getConnectionFactory() ); long increment = redisAtomicLong.getAndIncrement(); String id = String.format("%1$05d", increment); //5位数 return id; }}
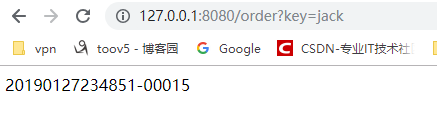
加上前缀:
import java.text.SimpleDateFormat;import java.util.Date;import org.springframework.beans.factory.annotation.Autowired;import org.springframework.data.redis.core.RedisTemplate;import org.springframework.data.redis.support.atomic.RedisAtomicLong;import org.springframework.web.bind.annotation.RequestMapping;import org.springframework.web.bind.annotation.RestController;@RestControllerpublic class OrderController { @Autowired private RedisTemplate redisTemplate; @RequestMapping("/order") public String order(String key) { RedisAtomicLong redisAtomicLong = new RedisAtomicLong(key, redisTemplate.getConnectionFactory() ); long increment = redisAtomicLong.getAndIncrement(); String id =prefix()+"-"+String.format("%1$05d", increment); //5位数 return id; } public static String prefix() { String temp_str = ""; Date dt = new Date(); // 最后的aa表示“上午”或“下午” HH表示24小时制 如果换成hh表示12小时制 SimpleDateFormat sdf = new SimpleDateFormat("yyyyMMddHHmmss"); temp_str = sdf.format(dt); return temp_str; }}
Redis如果做集群,会产生重复的问题!
@RequestMapping("/order1") public String order1(String key) { RedisAtomicLong redisAtomicLong = new RedisAtomicLong(key, redisTemplate.getConnectionFactory()); // // 起始值 // redisAtomicLong.set(10); // 设置步长加10!!!! redisAtomicLong.addAndGet(9); return redisAtomicLong.incrementAndGet() + ""; }
redis 的key的失效时间问题!
24h 第二天时间变了 不会重复了哦
Twitter的snowflake(雪花)算法 (跟UUID一样不用联网)
snowflake是Twitter开源的分布式ID生成算法,结果是一个long型的ID。其核心思想是:高位随机+毫秒数+机器码(数据中心+机器id)+10位的流水号码Github地址: https://github.com/twitter-archive/snowflakeSnowflake 原理:snowflake生产的ID是一个18位的long型数字,二进制结构表示如下(每部分用-分开):0 - 00000000 00000000 00000000 00000000 00000000 0 - 00000 - 00000 - 00000000 0000第一位未使用,接下来的41位为毫秒级时间(41位的长度可以使用69年,从1970-01-01 08:00:00),然后是5位datacenterId(最大支持2^5=32个,二进制表示从00000-11111,也即是十进制0-31),和5位workerId(最大支持2^5=32个,原理同datacenterId),所以datacenterId*workerId最多支持部署1024个节点,最后12位是毫秒内的计数(12位的计数顺序号支持每个节点每毫秒产生2^12=4096个ID序号).所有位数加起来共64位,恰好是一个Long型(转换为字符串长度为18).单台机器实例,通过时间戳保证前41位是唯一的,分布式系统多台机器实例下,通过对每个机器实例分配不同的datacenterId和workerId避免中间的10位碰撞。最后12位每毫秒从0递增生产ID,再提一次:每毫秒最多生成4096个ID,每秒可达4096000个。